A Visual Approach To Investigating Shared And Global Memory Behavior Of Cuda Kernels
|
A Visual Approach To Investigating Shared And Global Memory Behavior Of Cuda Kernels |
Abstract
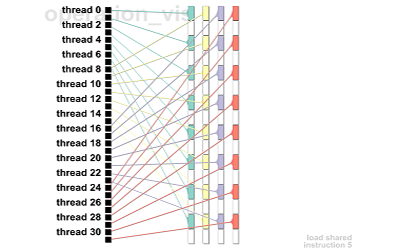
We present an approach to investigate the memory behavior of a parallel kernel executing on thousands of threads simultaneously within the CUDA architecture. Our top-down approach allows for quickly identifying any significant differences between the execution of the many blocks and warps. As interesting warps are identified, we allow further investigation of memory behavior by visualizing the shared memory bank conflicts and global memory coalescence, first with an overview of a single warp with many operations and, subsequently, with a detailed view of a single warp and a single operation. We demonstrate the strength of our approach in the context of a parallel matrix transpose kernel and a parallel 1D Haar Wavelet transform kernel.
Video
Downloads
![]()
![]()
Citation
Paul Rosen. A Visual Approach To Investigating Shared And Global Memory Behavior Of Cuda Kernels. Computer Graphics Forum, 2013.
Bibtex
@article{rosen2013visual,
title = {A Visual Approach to Investigating Shared and Global Memory Behavior of CUDA
Kernels},
author = {Rosen, Paul},
journal = {Computer Graphics Forum},
volume = {32},
pages = {161--170},
year = {2013},
note = {textit{Presented at EuroVis 2013.}},
abstract = {We present an approach to investigate the memory behavior of a parallel
kernel executing on thousands of threads simultaneously within the CUDA architecture.
Our top-down approach allows for quickly identifying any significant differences between
the execution of the many blocks and warps. As interesting warps are identified, we
allow further investigation of memory behavior by visualizing the shared memory bank
conflicts and global memory coalescence, first with an overview of a single warp with
many operations and, subsequently, with a detailed view of a single warp and a single
operation. We demonstrate the strength of our approach in the context of a parallel
matrix transpose kernel and a parallel 1D Haar Wavelet transform kernel.}
}